Mysql
大约 5 分钟
Mysql
安装
yum包
下载依赖
https://dev.mysql.com/downloads/repo/yum/
安装教程
https://dev.mysql.com/doc/mysql-yum-repo-quick-guide/en/
介绍💢
- 2019
- mysql 采用c或c++写的
Sql强化
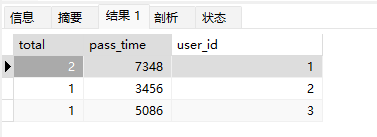
计算排名sql
- 关键函数: row_number() OVER
介绍
- 先统计符合的数据,在统计total,在总和pass_time,以total为优先排名pass_time次之排名,
- sql难度: ⭐⭐⭐⭐⭐
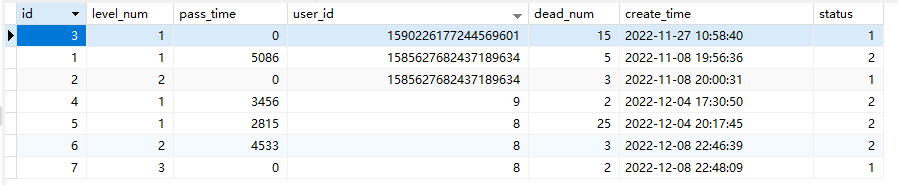
SELECT
COUNT(*) AS total,
sum( pass_time ) pass_time,
row_number() OVER ( ORDER BY COUNT(*) desc,sum( pass_time ) ) user_id
FROM
`t_ordeal`
WHERE
`status` = 2
GROUP BY
user_id
ORDER BY
total DESC,
pass_time
Mysql基本优化🏩
- 禁止使用 select *
- 只需要一条数据则 limit
- 购买高性能云盘
索引🌈
- 索引是否生效
- explain
- 索引失效场景
# 不等 where xx != 1
# 左%模糊查询 where xx like "%xx"
# 计算失效 where xx = n+1
# 使用函数 where xx(1,3) = 1
# 字符串使用数字查询 where xx = 111 注:如果 xx 为字符串字段那么此时是不走索引的
# or查询 where xx = 1 or nn = 2 注:如果只有一个字段建立索引那么是不会走索引,需要两个字段都建立
# not in where xx not in (11,22,33) 注:普通字段会失效,但主键字段不会失效
索引类型🍉
- 主键索引
- 普通索引
- 唯一索引
- 全文索引
- 空间索引
- 优点增加了查询速度,但减少了增删改速度,因为需要操作一下索引文件
事务👻
特性ACID⭐
- 原子性,要么都成功要么都失效
- 隔离性(隔离级别)
- 一致性,结果要与预期的一致
- 持久性,应该保存到磁盘中,才算完成整个事务
隔离级别🏧
- 读未提交(脏读),事务B能读到事务A未提交的数据,(会读出A事务已经修改的后的数据,未提交事务之前的数据)
- 影响:数据修改: 源a = 10,A事务 a = 10+10 回滚,B事务a = 20(脏数据)+10已提交。最终的数据=30,
- 总结:一个事务内的修改数据,会影响到其他事务的判断,对修改(加锁)
- 读已提交(不可重复读),
- 影响:数据修改:源a = 10,事务A读取 10,事务B读取 10,事务A修改 10+10,在读取等于20,事务B读取还是10,
- 总结:一个事务内修改数据后,修改前后读取的数据不一致,此情况在一般不会发生。
- 可重复读(有幻读问题)(默认):
- 影响:主键源a B事务查询a发现没有准备插入但未提交事务,A事务已经插入a唯一数据并提交事务,B事务开始提交,然后发现了冲突,很迷惑。
- 总结:一个事务多次查询数据的结果是一样的,如果另一个事务执行了插入,那么可能造成了幻读
- 串行化(以上问题都解决,效率低下),不能并发执行,事务只能一个个执行,效率低下。
锁🍑
乐观锁👻
- 基于业务实现,在数据库定义一个版本号进行实现。如果数据在其他地方已被修改,则异常。
- 适用快速返回结果的场景,读取频繁的场景
自旋锁(乐观锁递归)🍋
- 基于乐观锁循环执行业务,直至业务执行完成。
- 适用能够等待的业务场景,读取频繁的场景
备份🍉
提示
#语法 mysqldump -u用户名 -p 数据库名 > 数据库名.sql
# 示例
mysqldump -uroot -proot shiping > shipin.sql
定时备份命令🪲
- 安装mysql连接器
- yum install -y mariadb.x86_64 mariadb-libs.x86_64
- 每日两点备份一次
# 定时命令
crontab -e
0 2 * * * bash ${你的脚本目录}
备份脚本😎
- vim backup.sh
- 如果是docker必须指定-h参数,否则会有问题
#!/bin/bash
dbName="ink" #日期
createTime=`date +%Y-%m-%d_%H-%M-%S`
filePath="./sql/" #保存路径
mysqldump -uroot -proot -h127.0.0.1 $dbName> "$filePath$dbName-$createTime".sql
Docker🍊
读写分离👏
优化
- 300w数据+数据优化
- 1.通过索引优化查询
- 2.通过 id > n 进行条件限定。这样会减少扫描的行数
SELECT * FROM `app_user` WHERE id > 900000 LIMIT 10 # 会比下面的快很多
SELECT * FROM `app_user` LIMIT 900000,10
SELECT t.* FROM `app_user` t, (SELECT id FROM `app_user` WHERE id > 900000 LIMIT 10) k WHERE t.id = k.id # 提升不明显
快速模拟数据测试
- 原始教程 https://learnku.com/articles/75442
1.创建数据库
CREATE DATABASE `test_bai` -- 创建数据库
USE `test_bai` -- 切换对应的数据库
2.创建表
CREATE TABLE `app_user`(
`id` INT NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` VARCHAR(50) DEFAULT '' COMMENT '用户名称',
`email` VARCHAR(50) NOT NULL COMMENT '邮箱',
`phone` VARCHAR(20) DEFAULT '' COMMENT '手机号',
`gender` TINYINT DEFAULT '0' COMMENT '性别(0-男 : 1-女)',
`password` VARCHAR(100) NOT NULL COMMENT '密码',
`age` TINYINT DEFAULT '0' COMMENT '年龄',
`create_time` DATETIME DEFAULT NOW(),
`update_time` DATETIME DEFAULT NOW(),
PRIMARY KEY (`id`)
)ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT='app用户表'
3.插入数据
SET GLOBAL log_bin_trust_function_creators=TRUE; -- 创建函数一定要写这个
DELIMITER $$ -- 写函数之前必须要写,该标志
CREATE FUNCTION mock_data() -- 创建函数(方法)
RETURNS INT -- 返回类型
BEGIN -- 函数方法体开始
DECLARE num INT DEFAULT 1000000; -- 定义一个变量num为int类型。默认值为100 0000
DECLARE i INT DEFAULT 0;
WHILE i < num DO -- 循环条件
INSERT INTO app_user(`name`,`email`,`phone`,`gender`,`password`,`age`)
VALUES(CONCAT('用户',i),'2548928007qq.com',CONCAT('18',FLOOR(RAND() * ((999999999 - 100000000) + 1000000000))),FLOOR(RAND() * 2),UUID(),FLOOR(RAND() * 100));
SET i = i + 1; -- i自增
END WHILE; -- 循环结束
RETURN i;
END; -- 函数方法体结束
SELECT mock_data(); -- 调用函数